
Nature:为高维度医学成像设计可临床转化的人工

编译 | 王晔
文中探讨了高维临床影像数据所面临的特有挑战,并强调了开发机器学习系统所涉及的一些技术和伦理方面的考虑,更好地体现了影像模式的高维性质。此外,他们认为尝试解决可解释性、不确定性和偏见的方法应被视为所有临床机器学习系统的核心组成部分。
原文链接: AI 系统,所带来的一些问题和挑战的研究人员提供了一个模板。
我们预计,在可预见的未来,可用的高质量 "AI-ready "注释的医学数据集将仍然不能满足需求。回过头来分配临床事实标签需要临床专家投入大量的时间,而且将多机构的数据汇总起来公开发布也存在很大的障碍。除了需要以在硬放射学真实标签上训练的模型为特征的“诊断人工智能”之外,还需要根据潜在的更复杂的临床综合结果目标训练的 "疾病预测人工智能 "。具有标准化的图像采集协议和临床基本事实裁决的前瞻性数据收集,是构建具有配对临床结果的大规模多中心成像数据集的必要步骤。
大规模的多中心成像数据集会产生许多隐私和责任问题,这些问题与文件中嵌入的潜在敏感数据有关。医学数字成像和通信(DICOM)标准普遍被用来捕获、存储和提供医学图像的工作流程管理。成像文件(以.dcm文件或嵌套文件夹结构的形式存储)包含像素数据和相关元数据。众多的开源和专有工具可以帮助对 DICOM 文件进行去识别化。后端医院信息学框架,如Google Healthcare API,是一种清除可能包含敏感信息的元数据域的方法,也通过 "安全列表 "支持DICOM去标识化。
在面向用户方面,MIRC 临床试验处理器匿名器是一种流行的替代方法,尽管它需要使用某些遗留软件。有据可查的Python软件包(如pydicom)也可用于在使用或转给合作机构之前处理DICOM文件。然后可以提取成像数据并以各种机器可读格式存储。这些数据集可以迅速变得庞大且笨拙,虽然数据存储格式的细节超出了本观点的讨论范围,但医学成像 AI 的一个关键考虑因素是图像分辨率的保留。
自动去识别方法或脚本经常被提及的一个缺点是受保护的健康信息有可能被 "刻录 "在影像文件中。尽管有DICOM标准,但制造商的不同,使得难以通过 MIRC 临床试验处理器等工具来生成简单的规则,以屏蔽可能位于受保护健康信息的区域。我们建议使用一个简单的机器学习系统来屏蔽 "烧录 "的受保护健康信息。
以超声心动图为例,有一个预定义的扫描区域,在那里可以看到心脏。其他潜在的选择是基于机器学习的光学字符识别工具,以识别和屏蔽有印刷文本的区域。DICOM标签本身可用于提取扫描级信息和特定模式的标签。例如,在超声心动图和心脏磁共振成像 (MRI) 的情况下,可以轻松地从 DICOM 元数据中提取重要的扫描级别信息,例如采集帧速率和日期或 MRI 序列 (T1/T2)。
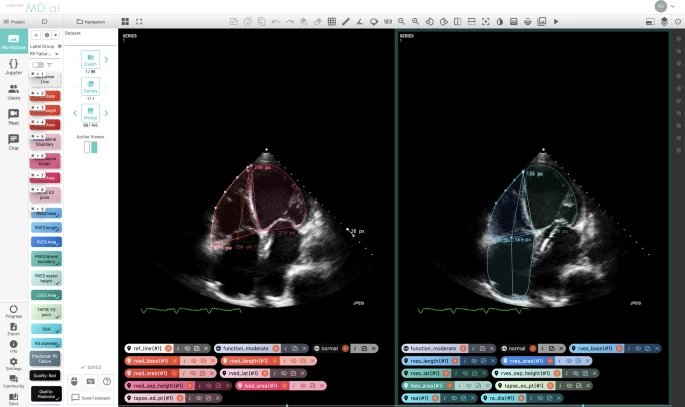
图1:基于云的协作式注释工作流程。基于云的工具可用于生成专家注释数据集,并通过安全连接与临床专家进行评估。图为MD.ai的一个实施方案,其中临床专家进行各种 2D 检测以测评心脏功能。
对于涉及人工智能系统与临床医生进行正面基准测试的研究工作,或在临床注释者的帮助下策划大型数据集,我们建议以DICOM格式存储扫描的副本。这样就可以通过可扩展和易于使用的云端注释工具进行部署。目前有几种解决方案用于分配扫描数据供临床专家评估。要求的范围可能从简单的扫描级标签到详细的特定领域的解剖学分割掩码。在我们的机构,我们部署了MD.ai (New York, New York),这是一个基于云的注释系统,可原生处理存储在机构批准的云存储提供商(谷歌云存储或亚马逊 AWS)上的 DICOM 文件。替代品提供类似的功能,如ePadLite(Stanford, California),它可以免费使用。基于云的注释方法的另一个优势是,扫描可以保持原始的分辨率和质量,实时协作模拟 "基于团队 "的临床决策,注释和标签可以很容易地导出用于下游分析。最重要的是,